○発表者:
堅山 耀太郎(東京大学 大学院工学系研究科 博士課程3年)
小林 徹也 (東京大学 生産技術研究所 准教授)
○発表のポイント:
◆免疫細胞の一種であるT細胞がもつ受容体の遺伝子配列データから、特定の感染症の感染状況や感染履歴を判別する新しい手法「MotifBoost」を考案した。複数のウイルス感染症に適用可能であることも示した。
◆この手法は、学習に用いる患者数が従来の手法の1/10程度の場合や、1患者あたりのデータ量が1/100程度と少ない場合でも、安定に感染状況を判定できた。
◆新型コロナウイルス等の新規感染症や、患者数の少ない免疫疾患等、データを集めづらい疾患の感染状況の判別や感染履歴の検出に応用できる可能性がある。
○発表概要:
哺乳類の免疫システムにおいて中心的な役割を果たすT細胞は、我々の体内で多様なT細胞受容体(注1)を持つ集団を成している。この多様性により未知の感染症なども含めた外敵が認識され、免疫応答が誘導されることで外敵が体内から排除される。また、感染により多様性が変化することで免疫記憶(注2)の一部が形成され、2度目の感染以降に迅速な免疫応答が誘起されると考えられている。近年、少量の血液等から、T細胞受容体の遺伝子配列データ(免疫レパトアデータ)を読み取ることができるようになり、将来的には血液検査によって免疫状態やさまざまな感染症・免疫疾患の感染履歴などを一度に判別できるようになると期待されている。しかし、T細胞受容体は約1013種類にのぼる膨大な多様性を有していると考えられ、また、個人差が非常に大きく、検出された遺伝子配列と特定の疾患を結びつけることは容易でない。そのため、従来の手法は検体数を多く集めることが可能な一部の疾患に対して、モデルの学習に数百以上の検体数が必要な統計的手法や複雑な深層学習手法を用いて解析がなされていた。
東京大学 大学院工学系研究科 博士課程3年の堅山 耀太郎 大学院生と同 生産技術研究所の小林 徹也 准教授は、T細胞受容体の遺伝子配列には、その性質を定める特徴的な部分配列が存在する場合があることに着目し、k-mer(注3)と呼ばれる配列の特徴量と機械学習手法を組み合わせた手法「MotifBoost」を考案した。そして、その手法により免疫状態の判別が可能であることをサイトメガロウイルス(CMV、注4)の感染に対して実証し、検体数が数十程度の場合でもCMVやヒト免疫不全ウイルス(HIV、注5)といった感染症の感染状況を学習・予測できることを示した。この結果は、新規感染症や希少疾患のような検体数が少ない対象でも免疫レパトアデータを活用して罹患状況の評価が行える可能性を示し、免疫レパトアデータの活用の対象となる新たな疾患を開拓することにつながると考えられる。
本研究成果は、2022年7月20日にFrontiers Mediaによる「Frontiers in Immunology」に掲載された。
○発表内容:
<研究背景>
免疫系は、我々の体を新型ウイルス感染症のような未知で多様な外敵から守る生体防御システムである。その中でもT細胞は、ヒトを含む脊椎動物の適応免疫システムの中で中心的な役目を果たしている。我々の体内には異なるT細胞受容体(TCR)を持つ多様なT細胞集団が存在しており、この受容体、つまりセンサーの多様なレパートリー(以下、T細胞レパトアと呼ぶ)によって未知の外敵を含む多様な侵入物を感知することが可能になっている。また、病原体による感染が起こると、病原体の認識に関わったT細胞受容体を持った細胞が増殖するなどしてT細胞レパトアの多様性が変化する。それが免疫記憶を形成し、再感染時に迅速な免疫応答が誘起される。したがって、T細胞レパトアには現在の免疫状態や過去の感染履歴の情報が反映・記憶されていると考えられ、それを読み解くことにより我々の免疫状態や様々な感染症・免疫疾患の感染履歴や将来のリスクまでも予測できると期待されている。
次世代シーケンサー(注6)の発展により、T細胞受容体遺伝子を配列データ(免疫レパトアデータ)として読み取ることができるようになった。これにより少量の血液から体内のT細胞受容体レパトアを定量的にデータとして取得できるようになり、その応用が期待されている。すでにいくつかの疾患に対するレパトアデータを用いた血液検査がアメリカ食品医薬品局(FDA)による承認を経て実用化されている。
しかし、T細胞レパトアの多様性は、T細胞の成熟過程で生じる受容体遺伝子のランダムな組み換えで作り出され、その可能な組み合わせは約1013種類と膨大である。また、一人の検体の血液などから計測できる受容体配列は、ヒトの約1011個のT細胞に対してたった約106~107個である。そのため従来の手法は数百の検体が得られる疾患を対象に、統計的手法や複雑な機械学習手法を用いて分類モデルを構築し、その適用範囲は限定的であった。特に、免疫疾患のような患者数が少ない疾患では検体数は数十程度かそれ以下の場合も多く、このような検体が少ない疾患に対しても利用可能な手法が求められていた。
<研究内容>
東京大学 大学院工学系研究科 博士課程3年の堅山耀太郎 大学院生と同 生産技術研究所の小林 徹也 准教授は、T細胞受容体配列にはその性質を定める特徴的な部分配列が存在する場合があることに着目し、k-merと呼ばれる部分配列モチーフによる特徴量作成手法に機械学習を組み合わせた手法(MotifBoost)を考案した(図1、図2)。そして同手法で免疫状態の特徴づけが可能であることをサイトメガロウィルス(CMV)の感染に対して実証し、CMVやヒト免疫不全ウィルス(HIV)といった感染症の感染状況を少ないデータで学習し、精度よく予測できることを確かめた。
1.提案手法
サンプル(検体)単位で部分配列(k-mer)の存在分布を計測して特徴量とし、小データに強いGBDT(Gradient Boosting Decision Tree、注7)と呼ばれる機械学習手法とData Augmentation(データ拡張、注8)を組み合わることで、サンプルに対して特定の疾患への感染の有無などを予測する機械学習手法を開発した。
2.少数データでの検出精度の検証を行った
提案手法と複数の既存手法との精度比較を行った。600以上の検体からなる大規模データで提案手法が既存手法と同等程度の精度を達成することを確認した。しかし、100検体以下では提案手法が精度を維持する一方で、既存手法の性能は大幅に低下することを示した。また、1検体あたりの受容体レパトアデータ数が通常の1%程度でも提案手法の場合は高い精度が維持されることを示した。提案手法は、CMVの複数のデータセットでも適用可能であり、また、HIV感染の有無の判定にも応用可能であることを示した。この結果は少ない患者数の場合だけでなく、少ない費用で実験が行われている場合にも提案手法が有効であることを示している。
3.提案手法の安定性を示した
提案手法と複数の既存手法で、同じデータセットに対しての結果の安定性を検証した。提案手法は繰り返し実験を行った場合でも一貫して同様の結果を示すのに対し、深層学習に基づく既存手法は同じデータセットからサンプリングされたデータであっても、含まれるサンプルが異なる場合に大きく精度が変わることがわかった。この結果は、本提案手法が幅広い実験条件やデータサイズにおいて安定した結果を出力することを示しており、他方で他手法では実際にはレパトアデータで判定ができる疾患を見逃してしまう可能性があることを示唆している。
4.k-mer特徴量の表現力を明らかにした
サンプルごとの部分配列(k-mer)の分布を可視化したところ、CMVの感染状況を入力することなく自然にCMVの感染サンプルと非感染サンプルが分離できることがわかった。この結果は、提案手法が特徴量として用いている部分配列(k-mer)の分布が免疫の状況をよく捉えられる優れた特徴量であることを示唆している。
<今後の予定>
レパトアデータは免疫システムの状態を定量化する鍵と考えられている。データが少ない状況において活用可能な本提案手法は、レパトアデータによる診断・状況評価が期待されている疾患に対して適用することで、レパトアデータの活用範囲を広げ、また、さらなるレパトアデータの活用を目指した今後の新たな解析手法の開発につながると期待される。
本研究は日本学術振興会科学研究費助成事業(20J21362、19H05799)、JST CREST(JPMJCR2011)などの助成や支援を受けて行われた。
○発表雑誌:
雑誌名:「Frontiers in Immunology」(オンライン版:7月20日)
論文タイトル:Comparative study of repertoire classification methods reveals data efficiency of k-mer feature extraction
著者:Yotaro Katayama, Tetsuya J. Kobayashi
DOI番号:10.3389/fimmu.2022.797640
○問い合わせ先:
東京大学 生産技術研究所
准教授 小林 徹也(こばやし てつや)
Tel:03-5452-6798 Fax:03-5452-6798
E-mail:tetsuya(末尾に"@sat.t.u-tokyo.ac.jp"をつけてください)
URL:https://research.crmind.net/index_jp.html
○用語解説:
(注1)T細胞受容体
免疫システムで主要な役割を果たすT細胞の表面に発現する抗原受容体。他の細胞の表面に発現しているMHCと呼ばれる分子上に提示される異物の一部(抗原ペプチド)を認識することで活性化し、免疫反応を起こす。1013ものパターンが生成されうると考えられており、異なる抗原ペプチド群を認識する。
(注2)免疫記憶
免疫系は、1度感染した病原体に再度感染した際に、1度目の時よりも迅速に応答する機能を有する。これを免疫記憶という。免疫の記憶は、感染時に病原体の認識に関わったT細胞やB細胞の一部が、メモリー細胞として長期に体内で生存するように変化することで実現されていると考えられている。また最近では、獲得免疫系のT細胞・B細胞だけではなく、自然免疫系の細胞にも類似の記憶が形成されることも見いだされている。
(注3)k-mer
DNA配列など限られたパターン(DNAの場合はA,T,C,Gの4種類)からなる生物学的な配列を、長さkの連続した部分配列の組み合わせに分解して解析する手法。一般に生物学的な配列は長さが定まっておらず、多くの機械学習アルゴリズムでは直接的に扱いにくい。k-merに分解することで、図2右上のようにどのような配列でもパターン数のk乗通りの部分配列の組み合わせ(それぞれの部分配列が何個存在するか)で表現できる。本研究ではアミノ酸配列(パターン数は20)を対象にしている。
(注4)サイトメガロウイルス(CMV)
ヒトヘルペスウイルスの1つ。1度感染すると、症状がない状態でも生涯体内に潜伏感染し続ける。免疫力が低下した場合などに活性化し症状を引き起こす「日和見感染症」の原因となる。男女問わず世界的に感染率は高いが、特に女性の場合は妊娠時に新生児に先天性の障害を引き起こすことがある。日本人成人女性の70%が感染していると推定されている。
(注5)ヒト免疫不全ウイルス(HIV)
後天性免疫不全症候群(AIDS)を引き起こすウイルス。免疫細胞に感染し破壊するため、感染が進行すると様々な感染症やガンを発症させる。
(注6)次世代シーケンサー
DNA分子の配列(A,T,C,Gの組み合わせ)を高速に定めることができる装置。
(注7)Gradient Boosting Decision Tree
勾配ブースティング決定木と呼ばれる機械学習アルゴリズム。図2右下のように単純な決定木を組み合わせて予測を行う。学習時には新しい決定木を勾配ブースティングと呼ばれる手法で追加する。この手法は、既存の決定木群の予測性能が低い部分を補うように新しい決定木を構築するため、従来のランダムに決定木を作成する手法に比べて性能が高いと考えられている。
(注8)Data Augmentation
既存のデータに人為的な加工を施すことで、新たなデータを実験的に取得することなく、機械学習アルゴリズムに与えるデータを増やす手法。免疫レパトアデータの収集にはドナーの募集、費用面で課題があり、データ数を増やすことが一般に難しいため重要である。本研究では免疫レパトアデータからサンプリングを行うことで新たな学習データとしている。
○添付資料:
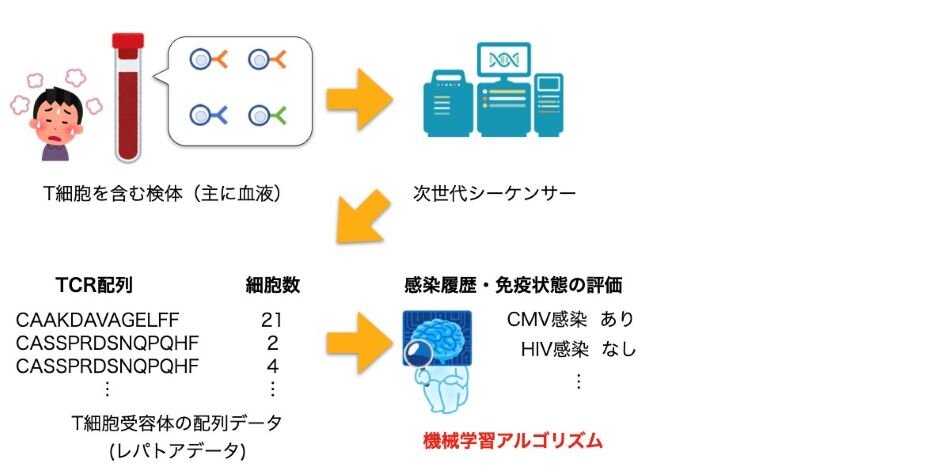
図1 T細胞受容体レパトアの機械学習とその応用
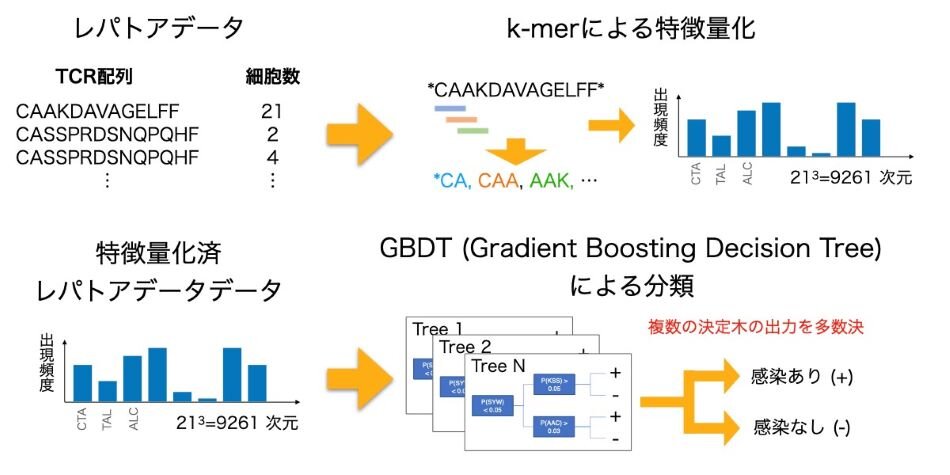
図2 提案手法(MotifBoost)の概要