○発表者
ホワン・イーフェイ(黄 逸飛、Yifei Huang、東京大学 大学院情報理工学系研究科
電子情報学専攻 博士課程1年生)
サイ・ビンショウ (蔡 敏捷、Minjie Cai、東京大学 生産技術研究所 特任研究員)
リ・シンキョウ (李 振強、Zhenqiang Li、東京大学 大学院情報理工学系研究科
電子情報学専攻 修士課程2年生)
佐藤 洋一 (東京大学 生産技術研究所 教授)
○発表のポイント
◆頭にカメラを装着し、視線の動きから人の行動を理解しようとする研究が注目され、視覚的に目立つ箇所や手の位置、頭の動きから視線の動きを予測する手法が報告されてきました。
◆今回、特定の作業中の視線の動きを記録した映像セットから、作業特有に見られるパターンをAIで学習させ、視線移動の予測精度を既存手法と比べて最大約40%改善することに成功しました。
◆本技術は、ものづくりの技能の伝承や、自閉症スペクトラム障害の早期スクリーニング、自動車の運転手の視認行動分析など、幅広い分野で活用が期待されます。
○発表概要
東京大学 生産技術研究所 ソシオグローバル情報工学研究センターの佐藤 洋一 教授らの研究グループは、頭部装着型カメラにより記録された「一人称視点映像(注1)」から、人の視線の動きをこれまでにない精度で予測する手法を開発しました。
人の詳細な行動の理解には、人がいつ何に注意を向けているのかを知ることが重要です。映像から人の視線がどう動くかを予測できれば、視線計測デバイスなどの特殊な装置を用いることなく人が何をどう見ているのかを知ることが可能となります。一方、人の視線の動きはその人物が行っている作業に強く依存することが知られていましたが、既存の一人称視点映像からの視線予測手法では、この作業依存性が考慮されていませんでした。
本研究では、例えば人がキッチンで料理をする中で、どのタイミングでどのような物からどのような物へ視線を動かすのかを、その作業中に記録した一人称視点映像と視線データから事前に学習することにより、新たな映像から、これまでにない精度で視線移動を予測することに成功しました。
本技術は、ものづくりの現場における技能の伝承や、自閉症スペクトラム障害の早期スクリーニング、自動車運転時の運転手の視認行動分析など、広く人の行動のセンシングと解析に関わるさまざまな分野での活用が期待されます。
この内容を取りまとめた論文は2018年9月10日(月)~13日(木)にドイツのミュンヘンで開催されるEuropean Conference on Computer Vision (ECCV 2018)において口頭発表論文として発表されます。
○発表内容
一人称視点映像からの視線位置を予測する試みは、深層学習を用いた手法も含め、これまでにも多く報告されてきました。しかしながら、これらは全て、人は視覚的に目立つ箇所に視線を向けやすいという視覚的顕著性のモデルや、手の位置や頭の動き(すなわち一人称視点映像の全体的な動き)に基づき視線を予測しようとするものでした。
一方、認知科学や視覚心理の分野では、同じ対象を見る場合でも、人は作業(タスク)として何を行っているかによって、その視線の動きが大きく異なることが定性的に知られていました。しかしながら、既存の視線予測の取り組みでは、この視線の動きのタスク依存性の重要性は認識されつつも、具体的な手法として実現が困難とされていました。
これに対し、本研究グループは、深層学習を用いた画像解析におけるアテンションモデルに着想を得て、タスクに依存する視線移動のパターンを考慮することにより、一人称視点映像から高い精度で視線位置を予測できる手法を開発しました。提案手法は、図1に示すとおり、前段のS-CNNとT-CNNによるエンコード部分(注2)に加えて、後段の視覚的顕著性に基づく視線予測モジュール(注3)と、今回新たに提案する視覚的注意移動予測モジュール(注4)によるデコード部分で構成され、最終的に両方のモジュールからの出力を統合ネットワークで統合することで視線位置の予測マップが得られます。
一人称視点映像解析の研究で用いられている標準ベンチマークデータセットを利用した評価実験により、最新の既存の視線予測手法と比較して、提案手法がより高い精度で視線位置を予測できることが確認されました(動画1)。
今後は、さらに広くさまざまタスク実行時の一人称視点映像を用いた評価や、ものづくりの現場における技能の伝承、自閉症スペクトラム障害の早期スクリーニング、自動車の運転手の視認行動分析などへの適用に取り組む予定です。
○発表雑誌
国際会議: European Conference on Computer Vision (ECCV 2018)(2018年9月10日(月)~13日(木)開催)
論文タイトル: Predicting Gaze in Egocentric Video by Learning Task-dependent Attention Transition
著者: Yifei Huang, Minjie Cai, Zhenqiang Li and Yoichi Sato
https://arxiv.org/abs/1803.09125
○問い合わせ先
東京大学 生産技術研究所 ソシオグローバル情報工学研究センター
教授 佐藤 洋一(さとう よういち)
Tel:03-5452-6278
研究室URL: http://www.hci.iis.u-tokyo.ac.jp/ja/
○用語解説
(注1)一人称視点映像
頭部装着型カメラにより記録される映像。防犯カメラなどの固定カメラで得られる映像では人の行動を外から観察した様子が記録されるのに対し、頭部装着型カメラの映像では装着者自身の視線から自己の行動の様子が記録されることから、「一人称視点」映像と呼ばれる。
(注2)S-CNNとT-CNNによるエンコード部分
S-CNN(Spatial-CNN)は映像の各カラー画像フレームを入力とする畳み込み型ニューラルネットワークであり、画像の見えに関する特徴量を出力する。T-CNN(Temporal-CNN)は映像から計算されたオプティカルフローと呼ばれる動き成分を入力とする畳み込みニューラルネットワークであり、画像の動きに関連した特徴量を出力する。S-CNNとT-CNNの組み合わせは、映像から見えと動きに関する特徴量を取り出す働きを持ち、映像からの行動解析で近年広く用いられている。
(注3)視線予測モジュール
Two-Stream CNNで得られた特徴量を入力とする逆畳み込みニューラルネットワークであり、大きな値ほど高い確率を表す視線位置の予測マップを出力する。
(注4)視覚的注意移動予測モジュール
注視状態推定器と再帰型ネットワークの一種であるLSTMネットワークを用いた注意移動予測器により構成されており、S-CNNとT-CNNによるエンコード部分の出力から注視状態推定器で視線移動がいつ起こっているのかを判定し、視線移動が起こったタイミングで、視線がどのようなカテゴリの物体からどのようなカテゴリの物体へ移動したのかをS-CNNでエンコードされた特徴マップをもとにLSTMで学習し、視線位置の予測マップを出力する。
○資料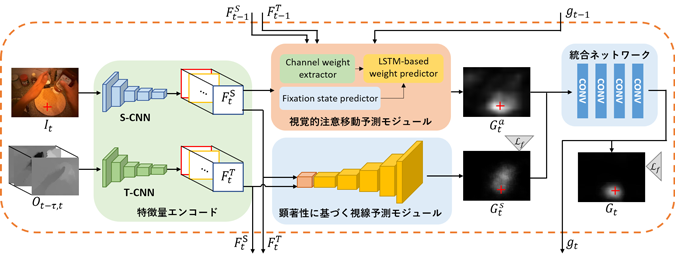
図1 提案手法の構成
動画1 提案手法の概要と処理結果の例